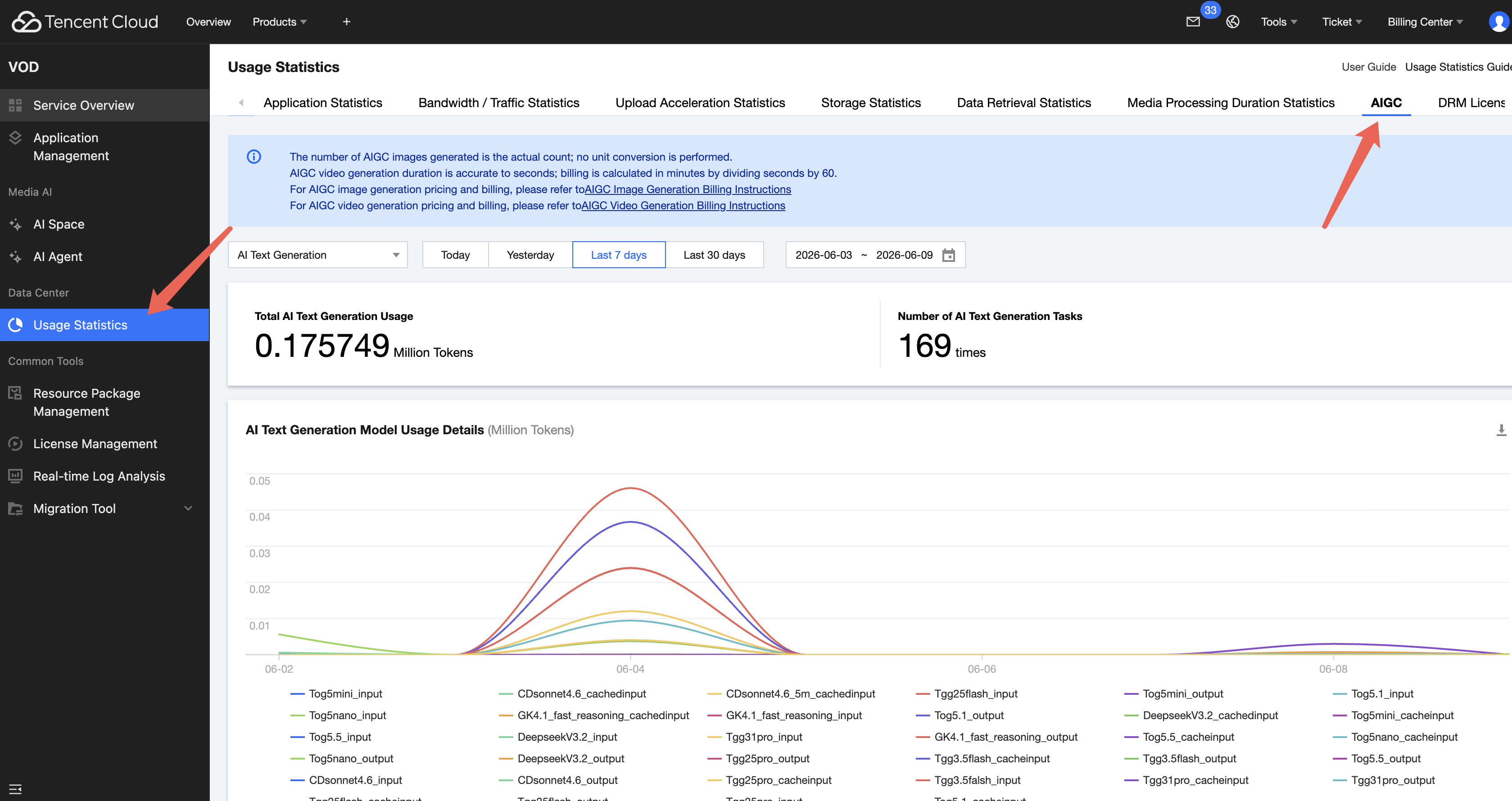
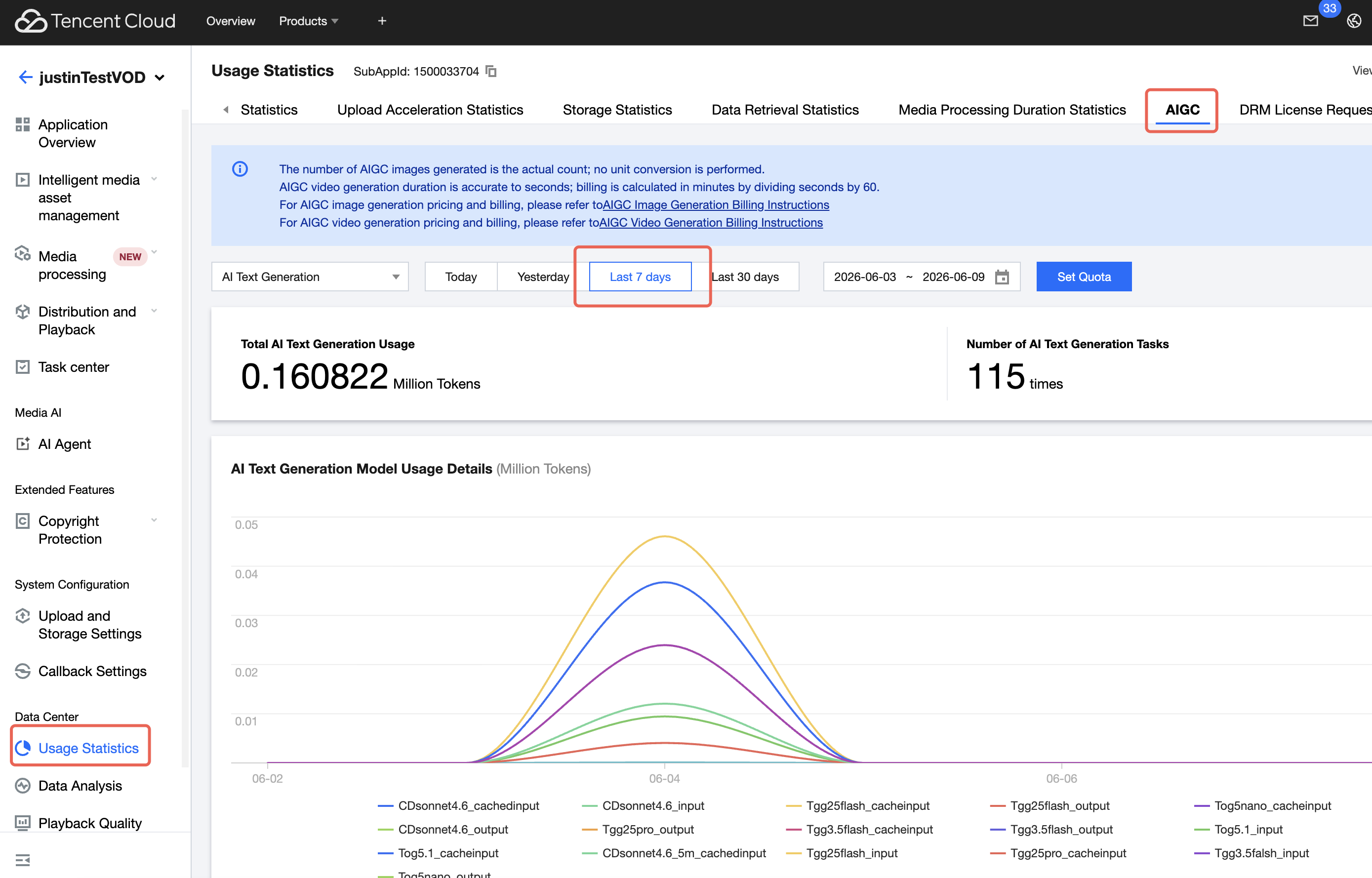
AIGC API Token 단위(Text) 또는 SubAppId 단위(Image, Video)로 사용 한도를 설정·조회·수정·삭제할 수 있습니다. 한도를 초과하면 LLM 호출이 HTTP 429 + insufficient_quota로 거부됩니다.
⚠
중요 — 호출 환경 제약
Endpoint: https://vod.tencentcloudapi.com 와 인터내셔널 도메인(https://vod.intl.tencentcloudapi.com) 모두 지원합니다. (과거 intl 도메인에서 InvalidAction을 반환하던 제약은 해소되어, 두 도메인 모두 정상 동작합니다.)
Tencent Cloud Python SDK 3.1.111 기준으로 본 4종 API는 SDK 모델에 미반영 상태입니다. 따라서 raw signed POST (TC3-HMAC-SHA256) 방식으로만 호출 가능합니다.
개요
Action
설명
필수 파라미터
DescribeAigcQuotas
Quota 조회
SubAppId, QuotaType
CreateAigcQuota
Quota 생성
SubAppId, QuotaType, QuotaLimit (Text는 ApiToken 추가 필수)
ModifyAigcQuota
Quota 수정
SubAppId, QuotaType, QuotaLimit (Text는 ApiToken 추가 필수)
DeleteAigcQuota
Quota 삭제
SubAppId, QuotaType (Text는 ApiToken 추가 필수)
공통 규약
항목
값
Endpoint
https://vod.tencentcloudapi.com 또는 https://vod.intl.tencentcloudapi.com (둘 다 동일 동작)
Service
vod
Version
2018-07-17
인증 방식
TC3-HMAC-SHA256 서명 (SecretId / SecretKey)
호출 방식
Raw signed POST (Python SDK 미반영)
QuotaType 차원
QuotaType
차원
ApiToken 필요 여부
Text
ApiToken 단위
필수
Image
SubAppId 단위
불필요
Video
SubAppId 단위
불필요
운영 가이드 — 실전 시나리오
예시: 신규 고객의 Text API Token에 "월 100콜 상당" 한도를 적용하는 표준 절차입니다. 비동기 집계 over-shoot(+38%)을 고려해 안전 마진을 적용한 흐름입니다.
위 표는 게이트웨이 GET /v1/models로 조회 가능한 호출 가능 모델을 정리한 것입니다. DeepSeek은 deepseek-v4-pro · deepseek-v4-flash 두 변종으로 제공되며, deepseek-v4(bare ID)로는 호출되지 않습니다. gpt-5.5-pro, hy3-preview는 현재 계정 리전에서 지원되지 않아 표에서 제외했습니다.
모델 스펙 · 호출 정책
💡
핵심 전제 — 게이트웨이 패스스루(passthrough) 구조
Text Generation은 OpenAI / Anthropic 호환 프로토콜을 그대로 전달(proxy)하는 게이트웨이입니다. 따라서 Context Window · Max Output · 입출력 모달리티 · reasoning 여부 등 모델 자체 스펙은 원본 제공사(OpenAI / Google / Anthropic / xAI 등)의 모델 스펙을 그대로 따릅니다. Tencent VOD 측은 이 값들을 별도로 재정의하거나 축소하지 않으며, /v1/models는 호출 가능한 model ID 목록만 반환할 뿐 스펙 메타데이터(context/caps)는 포함하지 않습니다.
B. 모델 스펙 (5~9번)
#
항목
기준 / 답변
5
Context Window (최대 입력 토큰)
원본 모델 스펙과 동일. 게이트웨이가 별도 캡을 두지 않습니다. 예: gpt-5.x·cd-opus-4.x·gemini-3.x 모두 각 제공사 공식 문서의 context window를 그대로 적용. 정확한 수치는 각 제공사 모델 카드 참조.
6
Max Output (최대 생성 토큰)
원본 모델 스펙과 동일. 요청 시 max_tokens로 상한 지정. 미지정 시 모델 기본 상한 적용.
7
Type (chat / reasoning)
요청 파라미터로 제어합니다. thinking_enabled=true 또는 reasoning_effort(none~xhigh)를 지원하는 모델이 reasoning(thinking) 계열입니다. 대표 reasoning 계열: gpt-5.x(reasoning), gk-4-20-reasoning·gk-4-1-fast-reasoning, gemini-*-pro thinking, cd-opus-*(extended thinking), deepseek-v3.2. 나머지(*-chat, *-nano/*-flash-lite 등)는 chat 위주.
8
입력 지원 (Text/Image/Audio/Video/File)
위 5.3 표의 「지원 입력」 열로 확인. 요약: OpenAI·GK·CD = Text + Image, Gemini = Text + Image + Audio + Video + File(가장 넓음), MiniMax·Kimi·GLM·DeepSeek = Text. (멀티모달은 5.4 Part 객체의 image_url/input_audio/file_url 사용)
9
출력/기능 지원 (Tools/Code 등)
Tools(Function Calling): 전 모델 지원(tools/tool_choice 파라미터, 단 Gemini는 function 도구만). Code: 텍스트 출력의 일부로 전 모델 가능(gpt-5.3-codex는 코드 특화). 이미지 생성 출력은 미지원 — 본 Text Generation은 텍스트 출력 전용이며, 이미지 생성은 Image Generation API를 사용하십시오. JSON 강제 출력은 response_format 지원.
C. 호출 정책 (10~12번)
#
항목
기준 / 답변
10
Rate limit (RPM/TPM)
기본값: 30 RPM · 30만 TPM이 계정/Token 단위로 적용됩니다(모델별 차등이 아니라 게이트웨이 공통 기본값). 모델별 개별 RPM/TPM 차등표는 공개 제공되지 않으며, 더 높은 한도가 필요하면 정식 접속 후 담당자에게 상향 신청하십시오. (호출량 자체의 누적 한도는 4. AIGC Quota 관리로 별도 제어)
11
거부 파라미터 (temperature/top_p/top_k)
게이트웨이는 파라미터를 그대로 전달하므로, 거부 여부는 원본 모델 정책을 따릅니다. 특히 reasoning(thinking) 계열은 temperature·top_p·top_k를 무시하거나 거부하는 경우가 많습니다(예: OpenAI reasoning 계열은 temperature 고정, 일부는 1 이외 값 거부). reasoning 호출 시에는 reasoning_effort로 제어하고 샘플링 파라미터는 생략하는 것을 권장합니다. top_k는 OpenAI 프로토콜 표준 파라미터가 아니므로 Anthropic/Gemini 경로에서만 유효합니다.
12
별칭 ↔ 원본 스펙 대응
모델 ID는 단순 별칭(alias)일 뿐, 별도 캡 축소 없이 원본 모델 스펙을 그대로 사용합니다. 즉 cd-opus-4.8 = Claude Opus 4.8과 동일한 context·output·기능 캡입니다(Tencent가 별도 캡을 두지 않음). 접두사 규칙: 아래 표 참조.
※ 12번 질문(별칭 대응) 명확화 — 모델 ID 접두사는 원본 제공사를 가리키는 별칭 규칙이며, 스펙은 원본과 동일합니다:
접두사
원본 제공사
예시 (게이트웨이 ID → 원본 모델)
gpt-
OpenAI
gpt-5.5 → GPT-5.5 (스펙 동일)
gemini-
Google
gemini-3.5-flash → Gemini 3.5 Flash
cd-
Anthropic (Claude)
cd-opus-4.8 → Claude Opus 4.8
gk-
xAI (Grok)
gk-4.3 → Grok 4.3
deepseek-
DeepSeek
deepseek-v4-pro → DeepSeek V4 Pro
glm-
Zhipu
glm-5.1 → GLM-5.1
kimi-
Moonshot
kimi-k2.6 → Kimi K2.6
minimax-
MiniMax
minimax-m2.7 → MiniMax M2.7
📌
스펙 정밀 수치가 필요할 때
Context Window·Max Output의 정확한 토큰 수, 모델별 RPM/TPM 차등표는 공개 문서로 일괄 제공되지 않습니다. (1) 모델 자체 스펙은 각 원본 제공사 공식 모델 카드를 기준으로 하고, (2) 게이트웨이 차원의 한도(기본 30 RPM·30만 TPM 상향 등)는 담당자에게 문의해 계정별로 확인하십시오.
5.4 Request Parameters (OpenAI Completions)
💡
Tip
Anthropic, Responses 프로토콜 파라미터는 각 공식 문서를 참조하십시오.
Parameter
Type
Description
model
required
String
AI 모델 지정 (예: gpt-5.1, cd-sonnet-4.6)
messages
required
Array
대화 메시지 목록. 각 메시지는 role과 content를 포함
stream
required
Boolean
스트리밍 여부. true: SSE 스트리밍 응답
thinking_enabled
optional
Boolean
추론(CoT) 모드 활성화. 지원 모델에서만 사용 가능
reasoning_effort
optional
String
추론 강도. 값: none / minimal / low / medium / high / xhigh. thinking_enabled와 동시 설정 시 reasoning_effort 우선 적용
temperature
optional
Float
출력 무작위성 (0~2, 기본 0.7)
max_tokens
optional
Integer
최대 생성 토큰 수
tools
optional
Array of ChatCompletionTool
도구 목록 (Function Calling). OpenAI 공식 문서 참조
tool_choice
optional
ChatCompletionToolChoiceOption
도구 선택 방식 ("auto" / "none" / "required" / 특정 도구 지정)
response_format
optional
Object
출력 형식 지정 (예: {"type": "json_object"})
messages 배열 내 객체 구조
Field
Type
Description
role
String
system: 시스템 지시 | user: 사용자 | assistant: AI 응답 | tool: 도구 결과
content
String | Array of Part
String일 때: 텍스트 메시지. Array일 때: Part 객체 배열 (멀티모달). role이 tool일 때: 도구 출력 결과
tool_calls
Array
role이 assistant일 때: 모델이 요청하는 도구 호출 목록 (OpenAI 프로토콜 참조). Gemini는 function 도구만 지원
tool_call_id
String
role이 tool일 때: 응답 중 tool_calls에 포함된 도구 호출 ID
extra_content
ExtraContent
Gemini 모델: role이 assistant일 때 추론 서명(thought_signature) 포함 가능
Part 객체 구조
Field
Type
Description
type
String
text: 텍스트 | image_url: 이미지 URL | input_audio: 오디오 | file: 파일/비디오
text
String
type이 text일 때 필수. 메시지 텍스트 내용
image_url
String
type이 image_url일 때 필수. 이미지 URL (data URL scheme 지원, 70MB 이내)
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://text-aigc.vod-qcloud.com/v1"
)
response = client.responses.create(
model="gpt-5.1",
input=[
{
"role": "user",
"content": [
{"type": "input_text", "text": "Hello, how are you?"}
]
}
],
stream=True
)
for event in response:
print(event)
7. Response 처리
7.1 Response Parameters
Parameter
Type
Description
id
String
응답 고유 ID
object
String
객체 유형 (예: chat.completion)
created
Integer
생성 타임스탬프 (Unix)
model
String
사용된 모델명
choices[].index
Integer
선택지 인덱스
choices[].message.role
String
응답 역할 (assistant)
choices[].message.content
String
응답 내용
choices[].message.reasoning_content
String
추론 과정 (thinking 모드 시)
choices[].finish_reason
String
종료 이유 (stop, length, tool_calls)
usage.prompt_tokens
Integer
입력 토큰 수
usage.completion_tokens
Integer
출력 토큰 수
usage.total_tokens
Integer
총 토큰 수
usage.prompt_tokens_details.cached_tokens
Integer
캐시된 입력 토큰 수 (캐시 hit 시)
usage.completion_tokens_details
Object
출력 토큰 상세 내역
usage.completion_tokens_details.reasoning_tokens
Integer
추론 토큰 수 (completion_tokens에 포함됨, 별도 가산 아님)
JSON Response Example
200
ℹ
Token 검산 공식
total_tokens = prompt_tokens + completion_tokens reasoning_tokens ⊆ completion_tokens (reasoning은 completion 안에 포함, 별도 가산 없음)
일반 모델(gpt-5-mini 등)도 자동 reasoning이 발생할 수 있음 — reasoning_tokens > 0이 reasoning 전용 모델만의 특성은 아닙니다.
ℹ
취소(abort) 정책
별도 abort/cancel API는 제공되지 않습니다. 진행 중 요청 취소는 HTTP connection close로만 가능하며, 서버 측 inference 즉시 중단은 보장되지 않습니다. 정산은 DescribeAigcUsageData API 일자별 집계를 단일 진실 소스로 사용하십시오.
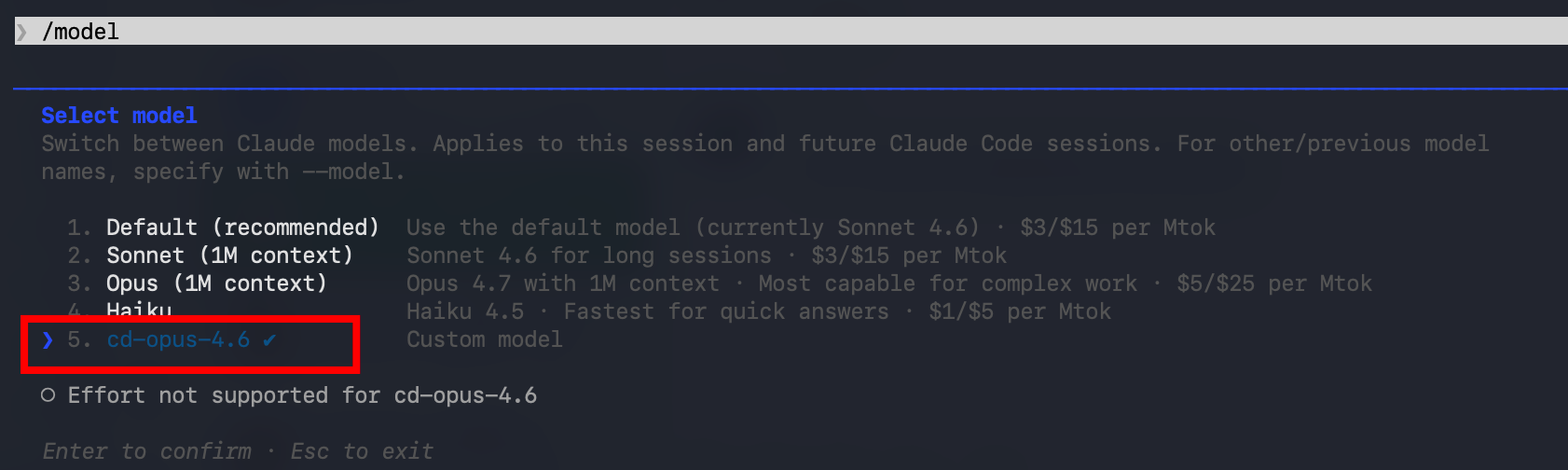
ANTHROPIC_BASE_URL에 /v1을 붙이지 않습니다. 모델 변경 시 ANTHROPIC_MODEL과 model 값을 동시에 수정 후 재시작하십시오.
Onboarding 스킵
경로: ~/.claude/.claude.json
JSON ~/.claude/.claude.json
{
"hasCompletedOnboarding": true
}
실행 및 확인
Bash Launch
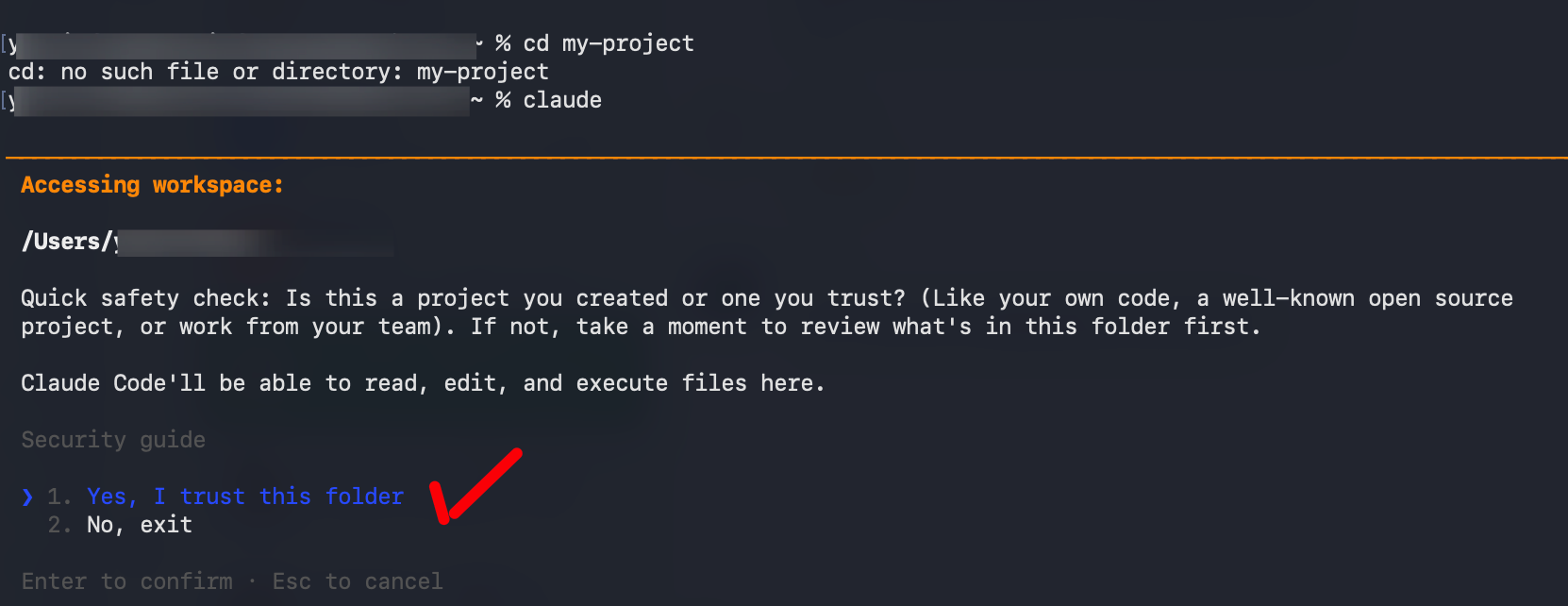
claude
# "Yes, I trust this folder" 선택
# /model 입력하여 현재 모델 확인
주의사항
⚠
Limitations
• Token 생성 후 약 1분간 동기화 필요 (401 발생 시 대기)
• 기본 Rate Limit: RPM 10, TPM 10만. 고빈도 사용 시 SubAppId와 함께 조정 요청
• VOD AIGC 기본 콘텐츠 컴플라이언스 검수가 활성화되어 있으며, 민감어 감지 시 400 에러 반환
• 시간 구간: start_time / end_time은 닫힌구간($gte / $lte)입니다.
• 정렬·페이징: 기본 timestamp 내림차순. skip = (page-1) × page_size.
• 첫 토큰 지연 샘플: first_token_count는 실제로 첫 토큰을 생성한 요청만 누적합니다. 첫 토큰 전에 실패한 순수 에러는 분모에서 제외되므로, first_token_avg_ms는 첫 토큰 출력에 성공한 요청의 평균 지연을 의미합니다.
• cache_hit_rate는 클램핑 없이 공식대로 계산되므로, 캐시 입력 토큰이 입력 토큰보다 많은 윈도우에서는 100%를 초과할 수 있습니다.
가능합니다. instruction 생략 시 messages의 system role로 설정하십시오.
API 호출
기본 동시 호출 한도
기본 RPM 30, TPM 30만. 정식 접속 후 조정 신청 가능합니다.
Quota
한도 초과 시 어떤 응답이 오나?
HTTP 429 + {"error":{"type":"insufficient_quota","message":"Text quota exceeded."}} — 4.5 참조.
법무
AI 호출 관련 컴플라이언스
미디어 처리 AI 관련 기능의 특별 약정을 참조하십시오.
1. Image Generation Overview
범용 이미지 생성 Task를 생성합니다. 텍스트 프롬프트 또는 참조 이미지를 기반으로 이미지를 생성하고 TaskId를 반환합니다.
TaskId를 받은 뒤 결과 조회 API 또는 콜백으로 생성 완료 상태와 결과 URL을 회수합니다.
1.1 API 정보
POSTvod.intl.tencentcloudapi.com
항목
값
Endpoint
vod.intl.tencentcloudapi.com
Method
POST
X-TC-Action
CreateAigcImageTask
X-TC-Version
2018-07-17
X-TC-Region
ap-seoul
1.2 지원 모델
모델명
설명
버전
GEM
Nano Banana — 고품질 범용 이미지 생성
2.53.03.1
OG
1K/2K/4K 해상도 이미지 생성
image2_lowimage2_mediumimage2_high
Qwen
Qwen 이미지 생성
0925
Seedream
고해상도 AI 아트 생성
4.55.0-lite
Kling
이미지 생성 + Outpainting (이미지 확장)
2.13.03.0-Omniscene
Vidu
고품질 이미지 생성
q2
Jimeng
Jimeng 이미지 생성 엔진
4.0
MJ (Midjourney)
고품질 아트 이미지, 참조 이미지 + Prompt 기반
v7
GPT-Image2
OpenAI 이미지 생성/편집, 다중 출력, 마스크, 투명 레이어
gpt-image-2
1.3 Supported Model Options
모델별 지원 해상도 · 종횡비(AspectRatio) · 최대 참조 이미지 수와, 해상도/종횡비를 지정하는 방식을 정리한 표입니다. 종횡비 지정 경로는 모델마다 다릅니다 — OutputConfig.AspectRatio(GEM · Kling · Vidu · OG), prompt 내 기술(Seedream · MJ), ExtInfo로 픽셀 직접 주입(Jimeng width/height · Hunyuan size · Qwen 자유).
⚠
size 지정 가능 모델
{"size":"2048x2048"} 같은 픽셀 직접 지정은 모든 모델이 받지 않습니다. size(또는 width/height)를 받는 모델은 Jimeng · Hunyuan · Qwen 뿐입니다. Hunyuan은 면적 상한(width×height ≤ 1024×1024)이 있어 2048×2048은 거부되고, Qwen은 2048×2048까지 허용됩니다. 그 외 모델은 AspectRatio + Resolution(1K/2K/4K)으로 크기를 지정합니다.
Multi-output via OutputImageCount, up to 8 images.
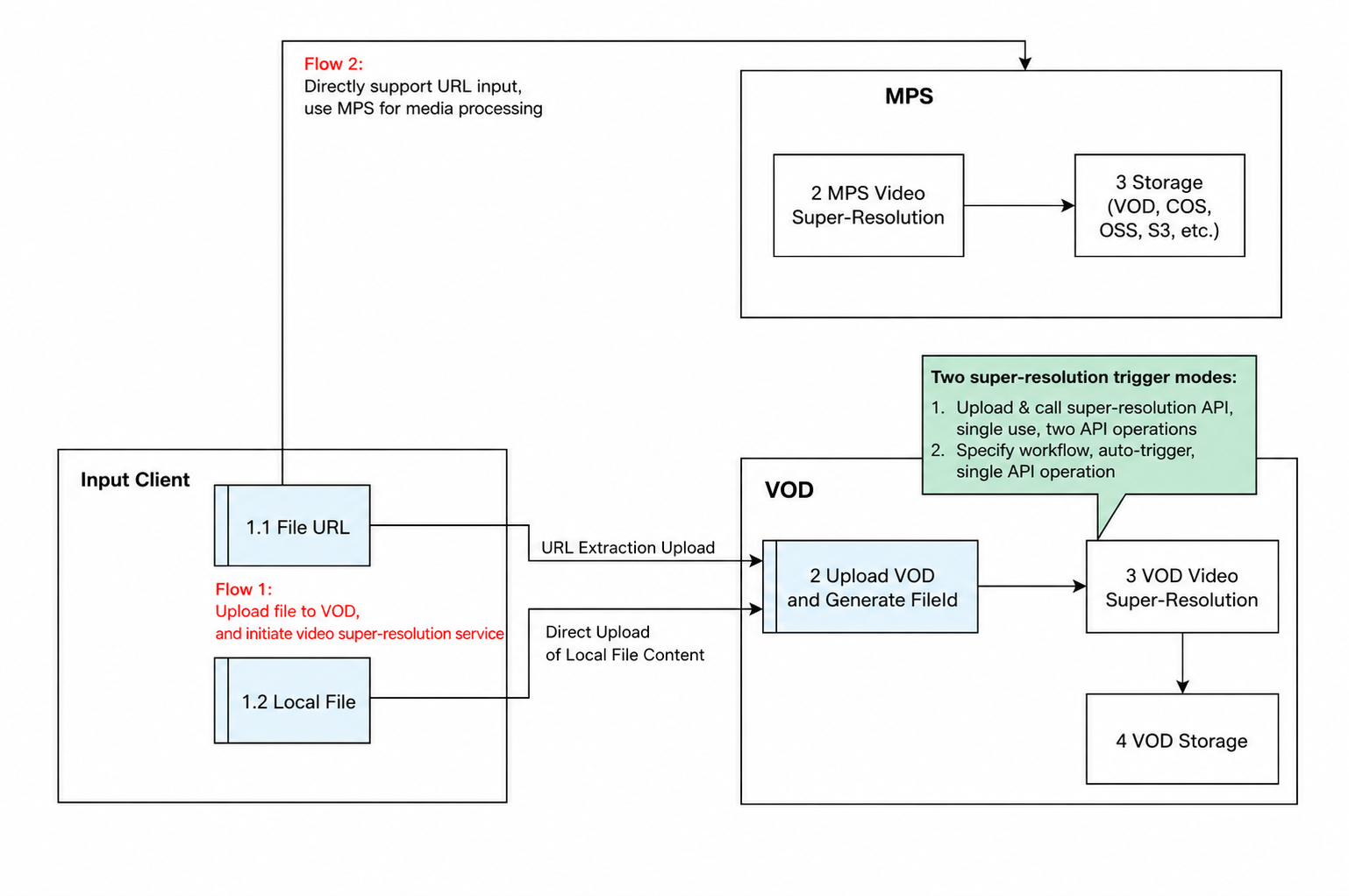
1.4 Architecture
Architecture Diagram
2. Quickstart
텍스트 프롬프트 한 줄로 첫 이미지 Task를 생성하는 최단 경로입니다. 아래 3 step을 따라 TaskId를 받고, 결과 조회 API로 결과 URL을 회수합니다.
2.1 Step 1 — Endpoint & 인증 헤더
Tencent Cloud Common API Endpoint와 SecretId/SecretKey 기반 TC3-HMAC-SHA256 서명을 사용합니다. 서명 생성 흐름과 raw signed POST 코드는 §4.7 Python raw signed POST 예제를 참고하십시오.
항목
값
Endpoint
https://vod.intl.tencentcloudapi.com
X-TC-Action
CreateAigcImageTask
X-TC-Version
2018-07-17
X-TC-Region
ap-seoul
Authorization
TC3-HMAC-SHA256 Credential=$YOUR_SECRET_ID/...
2.2 Step 2 — 요청 보내기
아래 cURL 1개를 그대로 실행하면 GEM 3.1 엔진에 prompt-only 요청이 전송되어 TaskId가 반환됩니다.
$YOUR_SECRET_ID, $YOUR_SECRET_KEY, $SUBAPP_ID는 본인 값으로 치환합니다. 전체 인증 헤더(Authorization) 생성은 §4.7 Python raw signed POST 예제를 그대로 사용할 수 있습니다.
GPT-Image2 엔진의 사용 패턴(다중 출력 / 마스크 편집 / 투명 레이어 / 커스텀 사이즈)은 §6.1 GPT-Image2 가이드 참조.
5.2 엔진별 전체 JSON
8개 엔진의 전체 Request Body를 한눈에 비교할 수 있도록 격자로 배치했습니다. 모든 엔진의 응답은 동일하게 { "Response": { "TaskId": "...", "RequestId": "..." } } 형태이며, 이후 DescribeAigcImageTask로 결과를 조회합니다.
{
"SubAppId": 1500044236,
"ModelName": "GPT-Image2",
"ModelVersion": "gpt-image-2",
"Prompt": "A professional product photo of wireless earbuds on a marble surface",
"OutputConfig": {"StorageMode": "Temporary", "AspectRatio": "1:1"}
}
다중 이미지 출력
OutputConfig에 ImageCount를 지정하여 한 요청으로 최대 4장 동시 생성.
MJ는 단일 요청당 고정 4장을 생성합니다. DescribeTaskDetail 결과에서 4장의 URL이 반환되며, 원하는 이미지를 선택하여 사용합니다. Prompt 내 --sref 등의 플래그는 MJ 자체 문법이며, API 호출 시 Prompt 문자열 안에 그대로 포함시켜 전달합니다.
7. 과금 & 한도
💰
Pricing
Image Generation 상세 과금 정책은 담당자에게 문의해 주십시오.
ℹ️
Quota
Image Generation 한도는 SubAppId 단위로 관리됩니다. Quota 조회/설정 API와 429 응답 처리 흐름은 Text Generation 페이지의 §4. AIGC Quota 관리를 참고하십시오.
1. Video Generation Overview
영상 생성 Task를 생성합니다. 텍스트, 이미지, 첫 프레임 입력을 기반으로 영상을 생성하고 TaskId를 반환합니다.
모델별로 지원 Duration, Resolution, AspectRatio가 다를 수 있으므로 엔진별 예시를 기준으로 시작합니다.
1.1 API 정보
POSTvod.intl.tencentcloudapi.com
항목
값
Endpoint
vod.intl.tencentcloudapi.com
Method
POST
X-TC-Action
CreateAigcVideoTask
X-TC-Version
2018-07-17
X-TC-Region
ap-seoul
1.2 지원 모델
모델명
설명
버전
Kling
전 기능 영상 모델 — Text/Image/Reference/Motion Control/Lip Sync/Digital Human/Multi-shot/Outpainting
1.62.02.12.52.63.03.0-OmniO13.0-motion-control
Vidu
Text/Image/First+Last Frame/Reference/Custom Subject/특효 템플릿 지원
q2q2-turboq2-proq3q3-proq3-turboq3-mix
PixVerse
Text/Image/First+Last Frame/Reference/비디오 편집 지원
V5.6V6.0C1
Hailuo (MiniMax Video)
고품질 영상 생성
022.32.3-fast
GV (Google Veo)
Google AI 영상 생성, 오디오 생성 지원
3.13.1-fast
OS (OpenAI Sora)
OpenAI 영상 생성
2.0
Jimeng
Jimeng 영상 생성 엔진
3.0pro
Seedance
Seedance 계열 고품질 영상
1.0-pro1.0-lite-i2v1.0-pro-fast1.5-pro
Mingmou
Mingmou 영상 생성
1.0
H2
H2 영상 생성 엔진
1.0
1.3 Supported Model Options
모델별 지원 해상도 · 종횡비 · 영상 길이(Duration) · 첫/끝 프레임 · 최대 참조 수 · 오디오 동시 생성 지원 여부를 정리한 표입니다. Duration · Resolution · AspectRatio는 OutputConfig 필드로 지정하며, 허용값은 모델마다 다릅니다.
⚠
duration / resolution / aspect_ratio 호환
{"duration":5,"resolution":"1080P","aspect_ratio":"16:9"} 조합은 Kling · Vidu에서 그대로 동작합니다. Hailuo(6s/10s만) · GV(8s 고정 등) · OS(720P 고정)처럼 길이/해상도가 특정값으로 고정된 모델은 5초 또는 1080P가 불가하니 모델 선택 시 표를 확인하십시오.
5s / 8s / 10s (v5.6; 10s not on 1080P) / 1–15s (v6, c1)
Supported
1–2 (first/last) / 7 (v5.6 ref) / 3 (c1 ref)
Yes (v6, c1)
See §6.3 PixVerse guide.
1.4 Architecture
Architecture Diagram
2. Quickstart
텍스트 프롬프트 한 줄로 첫 영상 Task를 생성하는 최단 경로입니다. 아래 3 step을 따라 TaskId를 받고, 결과 조회 API로 결과 영상 URL을 회수합니다.
2.1 Step 1 — Endpoint & 인증 헤더
Tencent Cloud Common API Endpoint와 SecretId/SecretKey 기반 TC3-HMAC-SHA256 서명을 사용합니다. 서명 생성 흐름과 raw signed POST 코드는 §4.7 Python raw signed POST 예제를 참고하십시오.
항목
값
Endpoint
https://vod.intl.tencentcloudapi.com
X-TC-Action
CreateAigcVideoTask
X-TC-Version
2018-07-17
X-TC-Region
ap-seoul
Authorization
TC3-HMAC-SHA256 Credential=$YOUR_SECRET_ID/...
2.2 Step 2 — 요청 보내기
아래 cURL 1개를 그대로 실행하면 Kling 3.0-Omni 엔진에 prompt-only 요청이 전송되어 TaskId가 반환됩니다. $YOUR_SECRET_ID, $YOUR_SECRET_KEY, $SUBAPP_ID는 본인 값으로 치환합니다. 전체 인증 헤더(Authorization) 생성은 §4.7 Python raw signed POST 예제를 그대로 사용할 수 있습니다.
Bash Quickstart cURL
curl -X POST https://vod.intl.tencentcloudapi.com \
-H "Content-Type: application/json; charset=utf-8" \
-H "X-TC-Action: CreateAigcVideoTask" \
-H "X-TC-Version: 2018-07-17" \
-H "X-TC-Region: ap-seoul" \
-H "Authorization: TC3-HMAC-SHA256 Credential=$YOUR_SECRET_ID/..." \
-d '{
"SubAppId": $SUBAPP_ID,
"ModelName": "Kling",
"ModelVersion": "3.0-Omni",
"Prompt": "A capybara mascot moves gently in a short studio video",
"OutputConfig": {
"Duration": 5,
"Resolution": "720P"
}
}'
StorageMode, Duration, Resolution, AspectRatio, AudioGeneration 등 — 상세는 §3.2 참조
InputRegion
optional
String
입력 파일 URL의 리전
SceneType
optional
String
모델별 Scene 타입
Seed
optional
Integer
결과 재현용 seed
SessionId
optional
String
3일간 중복 요청 방지용 ID
SessionContext
optional
String
콜백 시 함께 전달되는 context 값
ExtInfo
optional
String
모델별 확장 파라미터 전달용 JSON 문자열. 1차 키 AdditionalParameters 안에 동작제어·대사동기화·스마트 분할·음색 등 모델 고유 옵션을 넣는다 — 상세는 §3.4
3.2 OutputConfig 필드
Field
Type
Description
StorageMode
String
Temporary / Permanent
Duration
Integer
생성 영상 길이 (모델별 상이)
Resolution
String
720P, 1080P, 2K, 4K
AspectRatio
String
16:9, 9:16, 1:1, 4:3, 3:4
AudioGeneration
String
지원 모델에서 오디오 생성 Enabled/Disabled
EnhanceSwitch
String
초해상도 향상 (Super-Resolution) 활성화 (Enabled/Disabled)
OffPeak
String
오프피크(off-peak) 모드. Enabled 시 비혼잡 시간대에 처리해 비용을 절감 — 대신 완료까지 더 오래 걸릴 수 있음
FrameInterpolate
String
Vidu 스마트 프레임 보간. Enabled/Disabled. 중간 프레임을 보간해 더 부드러운 영상
LogoAdd
String
워터마크 로고 삽입 여부. 현재 Vidu만 지원 (Enabled/Disabled)
InputComplianceCheck
String
입력 콘텐츠 검수 (Enabled/Disabled)
OutputComplianceCheck
String
출력 콘텐츠 검수 (Enabled/Disabled)
OutputFormat
String
출력 파일 형식
3.3 FileInfos.N 필드 & 사용 패턴
FileInfos.N은 입력 이미지/비디오 배열입니다. 각 원소는 아래 필드로 입력 소스와 그 역할(첫 프레임·참조·편집 대상 등)을 지정합니다.
Field
Type
Description
Type
String
File(점박 미디어 FileId) / Url(접근 가능한 URL)
Category
String
Image / Video
FileId
String
Type=File일 때 유효
Url
String
Type=Url일 때 유효
Usage
String
입력 역할 구분 — FirstFrame(첫 프레임) / Reference(참조 프레임). 다중 참조 시 모든 원소가 Usage를 가져야 함
ReferenceType
String
참조 타입 (GV·Kling·PixVerse 적용). GV: asset(소재)/style(스타일); Kling+Video: feature(특징 참조)/base(편집 대상)
ObjectId
String
Vidu 주체 Id 또는 참조 모드 제어. 이미지 1장 + ObjectId 비어있음 → 첫 프레임 모드; 비어있지 않음 → 참조 모드. prompt에서 @ObjectId로 호출
VoiceId
String
Vidu-q2 음색 Id. 모든 이미지가 주체 Id를 가질 때 주체별 음색 지정 가능
KeepOriginalSound
String
Category=Video일 때 원본 음성 유지 여부 — Enabled/Disabled
사용 패턴
패턴
필드
Description
First frame
Usage = FirstFrame
첫 프레임 이미지 기준 영상 생성. 출력 종횡비는 입력 이미지 비율을 따름
Reference
Usage = Reference
스타일/캐릭터/오브젝트 참조용
First+Last frame
Usage = FirstFrame + LastFrameUrl/FileId
시작/끝 구도 지정. Kling 2.1 첫·끝 프레임은 1080P 필수
Subject reference
SubjectInfos.N
고정 주체(Subject) — 캐릭터/오브젝트/음성 ID (권장)
Object reference
ObjectId 지정
구방식 참조 — 한 장 이미지에 ObjectId를 비우면 첫 프레임, 채우면 참조
3.4 ExtInfo / AdditionalParameters (모델 확장)
동작 제어·대사 동기화·스마트 분할·음색 지정처럼 표준 파라미터로 표현할 수 없는 모델 고유 기능은 ExtInfo로 전달합니다. 대부분 SceneType으로 기능을 켜고, 세부 옵션을 AdditionalParameters에 담습니다.
⚠
2중 JSON 인코딩 구조
ExtInfo = {"AdditionalParameters": "<json-string>"} 이며, 그 값이 다시 모델 파라미터 JSON을 문자열로 인코딩한 것입니다. 즉 모델 파라미터를 두 번 JSON 문자열화해야 합니다. prompt 안에서는 <<<element_1>>> 형태로 주체(subject)/element를 참조합니다.
영상 생성 기능별 AdditionalParameters
기능 / SceneType
파라미터
설명
동작 제어 SceneType=motion_control (Kling 2.6 / 3.0)
keep_original_sound character_orientation
keep_original_sound: yes/no — 참조 영상 원음 유지 여부. character_orientation: image(이미지 인물 방향, 참조 영상 ≤10초) / video(영상 인물 방향, ≤30초)
대사 동기화 / 디지털 휴먼 SceneType=avatar_i2v (Kling)
sound_file 또는 audio_id
음성을 입에 맞춰 합성. sound_file: 오디오 URL/Base64(.mp3/.wav/.m4a/.aac, ≤5MB, 2~300초). audio_id·sound_file 둘 중 정확히 하나만 지정
대사 동기화 (간편) SceneType=lip_sync (Kling)
sound_file 또는 audio_id
avatar_i2v와 동일하게 입력 음성에 입모양을 맞추는 립싱크 전용 씬. 인물 영상/이미지에 음성을 합성
스마트 분할(분경) (Kling 3.0 계열)
multi_shot shot_type multi_prompt
multi_shot=true로 다중 컷 생성. shot_type=customize 시 multi_prompt 배열에 컷별 index/prompt/duration 지정. 미지정 시 모델이 프롬프트를 자동 분할
음색 지정 (Kling 2.6/3.0/3.0-omni)
voice_list
[{"voice_id": ...}] 형태. prompt에서 <<<voice_1>>>로 호출. Kling 2.6은 1080P에서만 음색 ID 지원
주체(subject) 참조 (구 방식) (Kling)
element_list
[{"element_id": ...}]. prompt에서 <<<element_1>>>로 참조. 신규는 SubjectInfos.N 권장 (→ §7.3)
특효 템플릿 SceneType=template_effect (Vidu)
template
장면 템플릿 이름(예: morphlab=폭발). 템플릿별 입력 요구가 다름 — Vidu 템플릿 센터 참조
고정 주체 참조 SceneType=subject_reference (Vidu)
SubjectInfos.N
여러 컷에 걸쳐 동일 인물/오브젝트를 일관되게 등장시키는 고정 주체 참조 씬
효과음 생성 (텍스트/영상) SceneType=sfx (Kling)
bgm_prompt asmr_mode
음효 프롬프트는 Prompt에, 배경음악 프롬프트는 bgm_prompt에. asmr_mode=true 시 디테일 음효 강화. 입력 영상은 VideoInfos로
음악 생성 SceneType=music (MiniMaxMusic)
lyrics
가사를 직접 지정. OutputConfig.OutputAudioFormat으로 출력 포맷(mp3 등) 지정
CreateAigcVideoTask는 비동기 API입니다. 호출 즉시 TaskId만 반환하고, 실제 영상은 백그라운드에서 생성됩니다. 영상 생성은 이미지보다 오래 걸리므로(모델·길이에 따라 수십 초~수 분) TaskId로 DescribeTaskDetail을 폴링하여 완료 여부와 결과 URL을 회수합니다.
4.1 CreateAigcVideoTask 응답
Parameter
Type
Description
TaskId
String
결과 조회용 Task ID. 이후 DescribeTaskDetail에 그대로 전달합니다.
RequestId
String
요청 추적용 ID. 문제 발생 시 기술지원 문의에 사용합니다.
⚠
세션 중복 제거(Dedup)
동일 SessionId로 보낸 요청은 3일간 중복 제거됩니다. 재시도 시 동일 결과를 받게 되므로, 새 영상을 원하면 SessionId를 변경하십시오.
4.2 작업 상태 (Lifecycle)
작업은 다음 상태를 순차적으로 거칩니다. FINISH 또는 FAIL이 종료 상태입니다. (영상 API는 처리 중 상태가 RUN입니다.)
WAIT→RUN→FINISH또는FAIL
상태
설명
권장 동작
WAIT
큐에서 대기 중
3~5초 간격으로 폴링 지속
RUN
영상 생성 처리 중
폴링 지속(영상은 시간이 더 걸림)
FINISH
완료 — 결과 URL 회수 가능
Output에서 영상 URL 추출
FAIL
실패
Message 확인 후 파라미터 수정·재시도
4.3 DescribeTaskDetail 폴링 예시
생성 요청과 동일한 인증 헤더로 DescribeTaskDetail을 호출합니다. Status가 FINISH가 될 때까지 3~5초 간격으로 반복하십시오.
11개 엔진의 전체 Request Body를 한눈에 비교할 수 있도록 격자로 배치했습니다. 모든 엔진의 응답은 동일하게 { "Response": { "TaskId": "...", "RequestId": "..." } } 형태이며, 이후 DescribeTaskDetail로 결과를 조회합니다.
Kling 3.0 시리즈는 Multi-shot (다중 숏)을 지원합니다. multi_shot: true 설정 시 다중 숏 모드 활성화.
• customize: multi_prompt로 각 숏의 시간+프롬프트 직접 지정 • intelligence: prompt 기반 자동 분할
JSON Multi-shot (Customize)
{"SubAppId":1500044236,"ModelName":"Kling","ModelVersion":"3.0-Omni","Prompt":"","OutputConfig":{"StorageMode":"Temporary","Duration":15,"Resolution":"1080P"},"ExtInfo":"{\"AdditionalParameters\":\"{\\\"multi_shot\\\": true, \\\"shot_type\\\": \\\"customize\\\", \\\"multi_prompt\\\": [{\\\"index\\\": 1, \\\"prompt\\\": \\\"A person sitting on a park bench\\\", \\\"duration\\\": \\\"5\\\"}, {\\\"index\\\": 2, \\\"prompt\\\": \\\"The person stands up and walks away\\\", \\\"duration\\\": \\\"5\\\"}, {\\\"index\\\": 3, \\\"prompt\\\": \\\"Wide shot of the empty park bench\\\", \\\"duration\\\": \\\"5\\\"}]}\"}"}
Outpainting (이미지 확장)
ModelVersion: scene — 이미지의 주변 영역을 확장합니다. 확장 후 전체 면적 ≤ 원본의 3배
JSON Outpainting Request
{"SubAppId":1500044236,"ModelName":"Kling","ModelVersion":"scene","FileInfos":[{"Type":"Url","Url":"https://example.com/input.jpg"}],"Prompt":"Extend the scene with a beautiful sunset sky","OutputConfig":{"StorageMode":"Temporary"},"ExtInfo":"{\"AdditionalParameters\":\"{\\\"up_expansion_ratio\\\": 0.5, \\\"down_expansion_ratio\\\": 0.2, \\\"left_expansion_ratio\\\": 0.3, \\\"right_expansion_ratio\\\": 0.3}\"}"}
커스텀 보이스 (Custom Voice)
Kling 2.6, 3.0, 3.0-Omni에서 사용자 정의 보이스를 지정하여 영상 내 음성을 합성할 수 있습니다. 사전 준비: CreateKlingCustomVoice API로 보이스 ID 생성 필요
JSON Voice ID Request
{"SubAppId":1500044236,"ModelName":"Kling","ModelVersion":"3.0-Omni","Prompt":"A narrator explaining the story","FileInfos":[{"Type":"Url","Category":"Image","Url":"https://example.com/scene.jpg","Usage":"FirstFrame"}],"OutputConfig":{"StorageMode":"Temporary","Duration":10,"Resolution":"1080P","AudioGeneration":"Enabled"},"ExtInfo":"{\"AdditionalParameters\":\"{\\\"voice_id\\\": \\\"YOUR_VOICE_ID\\\"}\"}"}
6.2 Vidu
Vidu 모델 상세 가이드
Vidu 시나리오별 사용법
커스텀 캐릭터 (Custom Subject)
동일 캐릭터/오브젝트를 여러 영상에서 재사용하려면 캐릭터를 먼저 등록합니다. Vidu는 사전 등록 없이 영상 호출 한 번에 캐릭터를 같이 넘기는 임시 모드도 지원합니다 — §7.5 Vidu 임시 캐릭터 참조.
사전 등록 흐름: CreateAigcAdvancedCustomElement 로 등록 → 약 30초 후 DescribeAigcAdvancedCustomElements 로 실제 Element Id 회수 → 이후 SubjectInfos.N.Id 로 참조. 자세한 워크플로는 §7.3 캐릭터 일관성 (Element) 참조.
Text-to-Video
JSON Vidu Text-to-Video
{"SubAppId":1500044236,"ModelName":"Vidu","ModelVersion":"q2","Prompt":"A golden retriever running on a beach at sunset","OutputConfig":{"StorageMode":"Temporary","Duration":4,"AspectRatio":"16:9"}}
이미지 → 영상 (Image-to-Video / 시작·끝 프레임)
첫 프레임: FileInfos[0].Usage = "FirstFrame". 끝 프레임 추가 시: LastFrameUrl 사용
JSON Vidu First+Last Frame
{"SubAppId":1500044236,"ModelName":"Vidu","ModelVersion":"q3-pro","Prompt":"Smooth transition from day to night","FileInfos":[{"Type":"Url","Category":"Image","Url":"https://example.com/day.jpg","Usage":"FirstFrame"}],"LastFrameUrl":"https://example.com/night.jpg","OutputConfig":{"StorageMode":"Temporary","Duration":4,"AspectRatio":"16:9"}}
참조 이미지 기반 영상 + q3-mix
다중 참조 이미지로 스타일/캐릭터를 참조하여 영상 생성. q3-mix는 더 세밀한 스타일 믹싱 지원.
JSON Vidu q3-mix Reference
{"SubAppId":1500044236,"ModelName":"Vidu","ModelVersion":"q3-mix","Prompt":"Character walks through a fantasy forest","FileInfos":[{"Type":"Url","Category":"Image","Url":"https://example.com/char.jpg","Usage":"Reference"},{"Type":"Url","Category":"Image","Url":"https://example.com/style.jpg","Usage":"Reference"}],"OutputConfig":{"StorageMode":"Temporary","Duration":4}}
6.3 PixVerse
PixVerse 모델 상세 가이드
PixVerse 시나리오별 사용법
PixVerse는 Text-to-Video, Image-to-Video, First+Last Frame, Reference, 비디오 편집을 지원합니다.
비디오 편집 (Video Edit)
기존 비디오를 입력으로 받아 스타일 변환, 효과 추가 등의 편집을 수행합니다. FileInfos에 Category: "Video"로 원본 비디오를 전달합니다.
JSON PixVerse Video Edit
{"SubAppId":1500044236,"ModelName":"PixVerse","ModelVersion":"V6.0","Prompt":"Transform to anime style","FileInfos":[{"Type":"Url","Category":"Video","Url":"https://example.com/input.mp4","Usage":"Reference"}],"OutputConfig":{"StorageMode":"Temporary"}}
7. 시각 일관성 고급 기법
동일한 액션(CreateAigcVideoTask) 위에서 영상의 시각적 일관성을 끌어올리는 기법들입니다. 해외(ap-seoul) 계정 기준으로 게이트웨이가 받는 파라미터 키 이름과 응답 형태를 정리했습니다.
🧩
한눈에 보기
기법
한 줄 요약
핵심 키
첫/끝 프레임 보간
두 이미지를 시작·끝으로 잡고 사이를 채움
FileInfos[Usage="FirstFrame"] + LastFrameUrl
다중 참조 (Reference)
여러 이미지를 스타일/구도 참고로 사용
FileInfos[Usage="Reference"]
캐릭터 일관성 (Element)
사전 등록한 캐릭터를 모든 영상에 동일하게 등장
SubjectInfos[].Id + <<<element_1>>>
Vidu 임시 캐릭터
등록 없이 호출 한 번에 캐릭터 동시 전달
SubjectInfos[Name+ImageUrls] + [@Name]
멀티 컷 (분할 촬영)
한 영상 안에서 카메라 워크가 여러 번 전환
ExtInfo 안 multi_shot JSON
7.1 첫 프레임 + 끝 프레임 보간
장면 N의 마지막 프레임 = 장면 N+1의 첫 프레임으로 강제해 컷 전환을 매끄럽게 만듭니다. 시작 이미지는 FileInfos[Usage="FirstFrame"], 끝 이미지는 LastFrameUrl로 넘깁니다.
참조 이미지가 2장을 넘어가면 같은 호출에서 LastFrameUrl을 같이 쓸 수 없습니다.
7.3 캐릭터 일관성 (Element)
여러 컷에 같은 등장 인물·캐릭터를 등장시키려면 사전 등록 후 ID로 호출합니다. 등록 → 목록 조회로 ID 회수 → 영상 생성에 사용 → (필요 시) 삭제의 4단계 흐름입니다.
Step 1 — 등록 (CreateAigcAdvancedCustomElement)
JSON Register Element
JSON
{
"SubAppId": 0,
"ElementName": "samurai-hero",
"ElementDescription": "main character of cyberpunk short film",
"ReferenceType": "image_refer",
"ElementImageList": "{\"frontal_image\":\"https://example.com/face.png\",\"refer_images\":[{\"image_url\":\"https://example.com/a.png\"},{\"image_url\":\"https://example.com/b.png\"}]}",
"DisableModeration": "True"
}
필드
의미
ElementName
표시용 이름, 20자 이하
ElementDescription
설명, 100자 이하
ReferenceType
image_refer (이미지 기반) 또는 video_refer (영상 기반)
ElementImageList
JSON 문자열. 안에 frontal_image(정면 1장) + refer_images(다른 각도 1~3장). 객체 그대로 넘기면 거부됨
DisableModeration
해외 계정에서는 "True"로 보내야 해외용 라이브러리에 등록됨
⚠️
JSON 문자열 주의
ElementImageList와 TagList는 객체가 아니라 JSON 문자열입니다. 응답으로 받는 TaskId(형식 {accountId}-CreateAigcAdvancedCustomElement-...t)는 등록 작업을 가리키는 임시 ID이며, 실제 캐릭터 ID는 약 30초 뒤 등록 목록 조회로 받아야 합니다.
Step 2 — 등록된 캐릭터 조회 (DescribeAigcAdvancedCustomElements)
Kling 3.0 계열은 한 호출 안에서 카메라 앵글이 여러 번 바뀌는 영상을 만들 수 있습니다. 키 자체는 ExtInfo 하나지만, ExtInfo가 JSON 문자열이고 그 안의 AdditionalParameters도 또 한 번 JSON 문자열입니다 — 즉 두 번 직렬화합니다.
모든 컷의 duration 합이 외부 OutputConfig.Duration과 같아야 합니다.
7.6 Python 호출 템플릿 (call_json)
공식 SDK의 typed 모델(models.CreateAigcVideoTaskRequest)은 SubjectInfos, LastFrameUrl, ExtInfo 같은 신규 필드를 아직 클래스 어트리뷰트로 노출하지 않는 경우가 있습니다. 가장 안전한 방법은 CommonClient.call_json(action, payload_dict)로 액션을 직접 호출하는 것입니다.
Python 등록 → ID 회수 → 영상 생성 → 폴링
import os, json, time
from tencentcloud.common import credential
from tencentcloud.common.profile.client_profile import ClientProfile
from tencentcloud.common.profile.http_profile import HttpProfile
from tencentcloud.common.common_client import CommonClient
cred = credential.Credential(
os.environ["TENCENTCLOUD_SECRET_ID"],
os.environ["TENCENTCLOUD_SECRET_KEY"],
)
hp = HttpProfile(); hp.endpoint = "vod.intl.tencentcloudapi.com"
cp = ClientProfile(); cp.httpProfile = hp
client = CommonClient("vod", "2018-07-17", cred, "ap-seoul", profile=cp)
# 1) 캐릭터 등록
elem_image_list = json.dumps({
"frontal_image": "https://example.com/face.png",
"refer_images": [
{"image_url": "https://example.com/a.png"},
{"image_url": "https://example.com/b.png"},
],
}, ensure_ascii=False)
resp = client.call_json("CreateAigcAdvancedCustomElement", {
"SubAppId": 0,
"ElementName": "samurai-hero",
"ElementDescription": "main character",
"ReferenceType": "image_refer",
"ElementImageList": elem_image_list,
"DisableModeration": "True",
})
register_task_id = resp["Response"]["TaskId"]
# 2) 약 30초 후 등록 목록 조회로 진짜 ID 회수
time.sleep(30)
list_resp = client.call_json("DescribeAigcAdvancedCustomElements", {"SubAppId": 0, "Limit": 50})
elem_id = next(
e["Id"] for e in list_resp["Response"]["ElementSet"]
if e["Name"] == "samurai-hero"
)
# 3) 캐릭터를 사용해 영상 생성
resp = client.call_json("CreateAigcVideoTask", {
"SubAppId": 0,
"ModelName": "Kling",
"ModelVersion": "3.0-Omni",
"SubjectInfos": [{"Id": elem_id}],
"Prompt": "<<<element_1>>> walks through a misty bamboo forest at dawn",
"OutputConfig": {"StorageMode": "Temporary", "Resolution": "1080P", "Duration": 5, "AspectRatio": "16:9"},
})
video_task_id = resp["Response"]["TaskId"]
# 4) 폴링 (DescribeTaskDetail → Response.AigcVideoTask)
while True:
detail = client.call_json("DescribeTaskDetail", {"SubAppId": 0, "TaskId": video_task_id})
avt = detail["Response"]["AigcVideoTask"]
status = avt["Status"] # PROCESSING / FINISH / FAIL
if status == "FINISH":
print("done:", avt["Output"]["FileInfoSet"][0]["FileUrl"]); break
if status == "FAIL":
print("failed:", avt.get("Message")); break
time.sleep(6)
📡
폴링 흐름
CreateAigcVideoTask 응답의 TaskId를 DescribeTaskDetail로 폴링합니다. 결과는 Response.AigcVideoTask 안에 잡히며 Status는 PROCESSING / FINISH / FAIL 셋 중 하나입니다. 완료 시 결과 URL은 Output.FileInfoSet[0].FileUrl에 있습니다. 폴링 간격은 6초가 적당하고, 5~10분 이상 걸리면 사실상 실패로 봐도 됩니다.
7.7 운영 메모 & 자주 보는 오류
항목
내용
결과 URL 보존
Temporary는 짧으면 24시간 안에 만료. 보존하려면 StorageMode: "Permanent"로 보내거나, 결과 mp4를 받아 별도 COS로 재업로드
SDK 호환
신규 필드는 typed 모델에 미노출일 수 있음 → CommonClient.call_json으로 우회가 가장 안전
검수 (Compliance)
해외 계정 / ap-seoul에서는 일부 InputComplianceCheck / OutputComplianceCheck 옵션이 거부됨. 게이트웨이 기본값에 맡기고 필요 시 자체 모더레이션 도입 권장
오류 코드
보통의 원인
UnknownParameter
키 이름이 잘못됨. 특히 단수/복수 — SubjectInfos가 맞고 SubjectInfo/Subjects는 거부됨
MissingParameter: ModelName
필수 키 누락
InvalidParameterValue.ModelVersionNotSupport
모델 + 버전 조합이 미지원
InvalidParameterValue.SubAppId
SubAppId가 잘못됨 (해외 계정은 보통 0 또는 본인 application id)
FailedOperation
액션 자체는 통했지만 내부 처리 실패 (가짜 이미지 / 정책 위반 / 학습 실패 등)
✅
고급 기법 요약
텍스트→비디오(Kling 3.0-Omni) · 첫 프레임→비디오(약 60초) · 첫/끝 프레임 보간(Kling 2.1, 약 30초) · 다중 참조 · 캐릭터 등록(ElementImageList JSON 문자열, 약 30초 후 ID 발급) · 캐릭터 사용(SubjectInfos) · 멀티 컷(ExtInfo 내 multi_shot)을 지원합니다. 파라미터 키는 복수형 SubjectInfos가 정확하며, 단수 SubjectInfo는 UnknownParameter로 거부됩니다.
8. 과금 & 한도
💰
Pricing
Video Generation 상세 과금 정책은 담당자에게 문의해 주십시오.
ℹ️
Quota
Video Generation 한도는 SubAppId 단위로 관리됩니다. Quota 조회/설정 API와 429 응답 처리 흐름은 Text Generation 페이지의 §4. AIGC Quota 관리를 참고하십시오.
1. Music Generation Overview
오디오 생성 Task를 생성합니다. 두 가지 모드를 지원합니다: SFX (Text-to-SFX) + 음악 생성 (Text-to-Music).
2. 3D 모델/장면 생성: CreateAigcVideoTask — SceneType: 3d_scene
1.1 API 정보
360 Panorama
POSTvod.tencentcloudapi.com
항목
값
X-TC-Action
CreateAigcImageTask
ModelName
Hunyuan
ModelVersion
3d_2.0
SceneType
3d_panorama
3D Scene/Model
POSTvod.tencentcloudapi.com
항목
값
X-TC-Action
CreateAigcVideoTask
ModelName
Hunyuan
ModelVersion
3d_2.0
SceneType
3d_scene
1.2 모델 기능
Mode
Input
Output
Use Case
세계 생성 (Text/Image→3D)
텍스트 프롬프트 (사실/카툰/고풍/SF 등), 단일 이미지 (사진/스케치/손그림)
360° 가상 3DGS/Mesh 장면, 자유 이동·물리 충돌 지원, Unity/UE 엔진 임포트 가능
게임 레벨, VR 공간, 인테리어, 문화 창작
세계 재건 (실경 3D 복제)
다시점 이미지 또는 단편 비디오 (환형 촬영)
1:1 고충실도 디지털 트윈, 측량·편집·시뮬레이션 가능
산업 트윈, 문화재 디지털화, 부동산 샘플룸
전경도 합성 (360 Panorama)
텍스트 / 단일 투시 이미지
무봉합 360° ERP 전경도
VR/AR, 영상 배경, 가상 라이브
1.3 출력 사양
항목
값
출력 포맷
3DGS (Gaussian Splatting), Mesh (GLB/FBX/OBJ), PLY (포인트 클라우드), 전경 비디오
생성 속도
텍스트→3D: 3~8분 / 이미지·비디오 재건: 5~15분
엔진 호환
Unity / Unreal Engine 네이티브 지원
오픈소스
2026.04.16 오픈소스 (모델 가중치 + 추론 코드 + 기술 백서, 상업 가능)
2. Parameters — Panorama (CreateAigcImageTask)
Parameter
Type
Description
SubAppId
required
Integer
VOD Sub Application ID (필수. 누락 시 MissingParameter 에러)
ModelName
required
String
Hunyuan
ModelVersion
required
String
3d_2.0
SceneType
required
String
3d_panorama
Prompt
required
String
생성 프롬프트
FileInfos.N
optional
Array
입력 이미지
OutputConfig.StorageMode
optional
String
Temporary / Permanent
3. Parameters — 3D Scene (CreateAigcVideoTask)
Parameter
Type
Description
SubAppId
required
Integer
VOD Sub Application ID (필수. 누락 시 MissingParameter 에러)
ModelName
required
String
Hunyuan
ModelVersion
required
String
3d_2.0
SceneType
required
String
3d_scene
Prompt
required
String
생성 프롬프트
FileInfos.N
optional
Array
입력 이미지
OutputConfig.StorageMode
optional
String
Temporary / Permanent
OutputConfig.Duration
optional
Integer
출력 길이 (초)
OutputConfig.Resolution
optional
String
1080P 등
OutputConfig.AudioGeneration
optional
String
Enabled / Disabled
4. Architecture
Architecture Diagram
5. 코드 예시
5.1 360 Panorama
Hunyuan 3D CreateAigcImageTask (Panorama)
JSON
{
"SubAppId": 1500044236,
"ModelName": "Hunyuan",
"ModelVersion": "3d_2.0",
"Prompt": "A futuristic cyberpunk city at night with neon lights",
"OutputConfig": {
"StorageMode": "Permanent"
},
"SceneType": "3d_panorama"
}
5.2 3D Scene Generation
Hunyuan 3D CreateAigcVideoTask (3D Scene)
JSON
{
"SubAppId": 1500044236,
"ModelName": "Hunyuan",
"ModelVersion": "3d_2.0",
"Prompt": "A traditional Korean hanok village surrounded by autumn foliage, photorealistic rendering, 8K resolution",
"OutputConfig": {
"StorageMode": "Temporary",
"Duration": 16,
"Resolution": "1080P",
"AudioGeneration": "Enabled"
},
"SceneType": "3d_scene"
}
⚠
Status 처리 주의
종료 상태는 FINISH 또는 DONE 둘 다 가능합니다 (호출 경로에 따라 상이). 반드시 양쪽 모두 체크하십시오. 또한 ErrCode가 0이 아니면 실패이므로 Status만으로 성공을 판단하지 마세요.
⏱
처리 시간 가이드
Panorama: 약 1분 (58~74초) Scene (3D Video): 5~15분 이상 (단순 5초 1080P도 25분+ 소요 케이스 관측)
⚠
동시 실행 제한
모델 패밀리(Image/Video)별 동시 1 task 권장. 초과 시 Status=FINISH + ErrCode=70000 + "Generate task reached the maximum concurrency."로 즉시 종료됩니다. ErrCode 검사가 필수입니다.
6. 과금 안내
💰
Pricing
요금 관련 상세 정보는 AIGC 가격 가이드를 참고하십시오.
ℹ️ 담당자에게 MPS로 사용을 안내받은 경우에만 아래 내용을 참고해주십시오.
1. MPS AIGC Overview
MPS(Media Processing Service) 엔드포인트를 통한 AIGC 콘텐츠 생성 가이드입니다. MPaaS AIGC(VOD 엔드포인트)와 동일한 모델 패밀리를 사용하며, 인증 방식(TC3-HMAC-SHA256)과 파라미터 구조가 다릅니다. 본 문서의 모든 스키마는 실제 호출로 검증되었습니다.
⚠
MPaaS AIGC vs MPS AIGC
MPaaS AIGC (VOD)
MPS AIGC
Endpoint
vod.tencentcloudapi.com
mps.intl.tencentcloudapi.com
인증
AIGC API Token (Bearer)
SecretId/SecretKey (TC3-HMAC-SHA256)
결과 저장
SubAppId 내 미디어
임시 URL(약 12h) 또는 StoreCosParam(영구 COS)
SDK
tencentcloud-sdk-python (vod)
tencentcloud-sdk-python (mps)
API Version
2018-07-17
2019-06-12
1.1 공통 API 정보
항목
값
Endpoint
mps.intl.tencentcloudapi.com
API Version
2019-06-12
Region
ap-seoul (Intl) / ap-guangzhou (China)
인증
TC3-HMAC-SHA256 (SecretId + SecretKey)
Method
POST
Content-Type
application/json
1.2 지원 모델 — Image
모델명
설명
버전
GEM
Nano Banana — 고품질 범용 이미지 생성
2.53.03.1
OG
1K/2K/4K 해상도 이미지 생성
image2_lowimage2_mediumimage2_high
Qwen
Qwen 이미지 생성
0925
Seedream
고해상도 AI 아트 생성
4.55.0-lite
Kling
이미지 생성 + Outpainting
2.13.03.0-Omniscene
Vidu
고품질 이미지 생성
q2
Jimeng
Jimeng 이미지 생성 엔진
4.0
MJ (Midjourney)
고품질 아트 이미지, 참조 + Prompt 기반
v7
GPT-Image2
OpenAI 이미지 생성/편집, 마스크, 투명 레이어
gpt-image-2
1.3 지원 모델 — Video
모델명
설명
버전
Kling
전체 모델 영상 — Text/Image/Reference/Motion Control/Lip Sync/Multi-shot/Outpainting